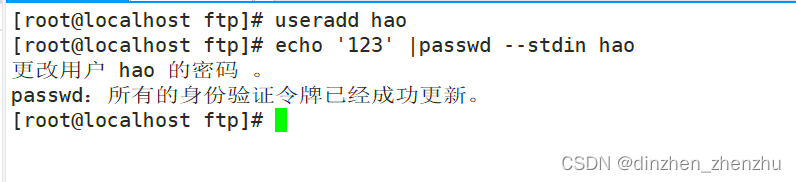
-
在进行表操作之前,一定要use选中数据库
-
注释:在SQL中可以使用
--空格+描述 来表示注释说明 -
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母。
文章目录
- 数据库约束
- 约束类型
- NOT NULL约束
- UNIQUE:唯一约束
- DEFAULT:默认值约束
- PRIMARY KEY:主键约束
- FOREIGN KEY:外键约束
- CHECK约束(了解)
- 新增(Create)
- 全列插入
- 一次插入多行记录
- 指定列插入
- 插入时间
- 插入查询结果(不用values关键字)
- SQL是"弱类型"的编程语言,和Java这种"强类型"的编程语言是不一样的
- 查询(Retrieve)
- 全列查询
- 指定列查询
- 查询字段为表达式
- 别名
- 去重:DISTINCT
- 排序:ORDER BY
- 条件查询:WHERE
- 分页查询:LIMIT
- 聚合查询(行与行之间的运算)
- 聚合函数
- 分组查询: GROUP BY子句
- 给聚合查询指定条件
- 聚合之前的条件(WHERE 在 group by 之前)
- 聚合之后的条件(HAVING 在 group by 之后)
- 联合查询(多表查询)
- 内连接
- 外连接
- 自连接
- 子查询
- 合并查询
- 修改(Update)
- 删除(Delete)
- PS
数据库约束
数据库约束可以理解成数据库提供的一种针对 数据合法性 验证的机制
约束类型
- NOT NULL - 指示某列不能存储 NULL 值,表里的内容是必填项
- UNIQUE - 保证某列的每行必须是唯一的值(不能重复),每次插入/修改都会先触发查询,如果值已经存在,就会插入/修改失败
- DEFAULT - 指定没有被赋值的列的默认值。不进行任何指定,默认值就是NULL
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。(相当于一条记录的身份标识)
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。MySQL数据库对CHECK子句进行分析,但是忽略CHECK子句。也就是不会报错,但是也不会生效。check指定条件,插入/修改数据时数据符合条件才能插入/修改成功;不符合条件则失败
NOT NULL约束
指定某列不为空:

UNIQUE:唯一约束
指定列的内容唯一的、不重复的:


DEFAULT:默认值约束
指定不插入数据时的默认值:

PRIMARY KEY:主键约束
- 不能为null
- 不能重复
相当于NOT NULL 和 UNIQUE 的结合
指定id列为主键:

一般给表设定主键使用数字(整数形式),很少使用字符串.
-
一个表只能有一个主键

-
一个主键不一定只针对一个列(联合主键----把多个列的内容联合到一起,共同构成一个主键),很少使用这个功能
-
当某个列集合了
not null和unique就成为主键了

一般使用整数 id 作为主键,但id的值该如何选择呢?
MySQL提供了"自增主键", 对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,赋值为最大值+1。

- auto:自动
- increment:增加
此时插入数据,主键的值就不用手动指定了

当然还可以手动指定,不一定依赖自增主键

如果把 id = 100 和 id = 101 删去,按理来说是从102开始自增,但不知道为啥我的会跳号

4~102这一批id,如果不手动指定就浪费了,如果不想浪费可以不依赖自动增键主动添加

自增主键本质 是MySQL服务器存储了当前表中最大的id,再进一步进行累加的。基于分布式系统存储数据的时候,MySQL自增主键就无能为力了.
在分布式系统中,如何生成唯一id?
最简单最朴素的方式: 时间戳 + 机器编号 + 随机数
再计算哈希值得到一个整数,这个整数可以作为id
简单介绍用
md5计算hash值的特性
- 定长. 无论输入的字符串多长,最终计算的hash值都是一样长的(作为校验和的一种方式)
- 分散. 输入的字符串,哪怕只有一点点不一样,得到的 hash值 都会差异很大(成为hash 算法的根本)
- 不可逆. 计算出的hash值理论上无法还原成原来的字符串(可以作为一种加密手段)
FOREIGN KEY:外键约束
外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)
案例:
插入 student 表的classId 必须要在 class 表的classId中存在,插入的学生才有意义(从属于某个班级)

此时,外键就让student 的 classId 就和 class 表的 classId 建立了联系.也就是student classId 中的值,必须要在 class 表的 classId 中存在. class 表就对 student 表产生了制约
- 父表中被引用的列必须是主键或是 unique
- 把 class 表(制约别人的表) 称为"父表"(parent table)
- 把 student 表(被制约的表) 称为"子表"(child table)
父表可以删除/修改没有被子表引用的记录,但如果被引用了就不能删除/修改了.
子表不能随意插入/修改(外键必须在父表中)
CHECK约束(了解)
MySQL使用时不报错,但忽略该约束:
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);
新增(Create)
全列插入
insert into 表名 values (值, 值...);
- 可以省略into
- values是关键字
一次插入多行记录
insert into 表名 values(值, 值...), (值, 值...), (值, 值...)...;
一次插入多条记录往往比一次插入一条记录,分多次插入的效率要高
MySQL是客户端 - 服务器结构的程序
客户端中执行的每个操作,都会通过网络请求发送给服务器,而服务器返回一个响应内容
虽然请求中包含了更多的数据,但网络开销更小了.网络开销对效率的影响大
指定列插入
insert into 表名(列名, 列名...) values(值, 值...);
列名个数和顺序无需和表头信息一致,只需保证列名是存在的
插入时间

'2024-04-22 11:13:00'是一个标准的时间格式化写法
有时,插入的数据要指定当前系统的时间,MySQL有一个专门的函数now()来获取

插入查询结果(不用values关键字)
需要确保查询到的结果集合(列数/类型/顺序),要和待插入表的列数/类型/顺序匹配
语法:
INSERT INTO 表名 [列名,列名...] SELECT ...;
SQL是"弱类型"的编程语言,和Java这种"强类型"的编程语言是不一样的
- 强类型和弱类型的区别:是否支持隐式类型转换
- 静态类型和动态类型的区别: 一个变量的类型,能否在程序运行过程中发生改变,不允许改变的是静态类型,允许改变的就是动态类型. C,Java属于静态类型; Python,JS属于动态类型
- SQL一般不会谈到变量这个概念

- SQL隐式类型转换

‘100’ 转换成 100
2 转换成 ‘2’

- Java显示类型转换
1.整型转字符串

2.字符串转整型

一个编程语言,越支持"隐式类型转换",类型系统就越弱.越不支持"隐式类型转换", 类型系统就越强
查询(Retrieve)
查询的所有操作都不会影响数据库服务器硬盘上存储的数据
全列查询
select * from 表名;
能够查询出表中所有行和列
-- 通常情况下不建议使用 * 进行全列查询
-- 1. 查询的列越多,意味着需要传输的数据量越大;
-- 2. 可能会影响到索引的使用。
指定列查询
select 列名, 列名... from 表名;
确保列名是存在合法的
列的顺序不需要按定义表的顺序来
查询字段为表达式
查询的结果不仅仅是列,而是把列代入到表达式中进行运算的结果
表达式查询,只是针对服务器响应得到的临时结果进行计算,不影响服务器硬盘上存储的数据本体
SQL中进行算术运算的时候,如果其中某个操作数是NULL,最后的计算结果也就是NULL了
-- 表达式不包含字段
SELECT id, name, 10 FROM exam_result;
-- 表达式包含一个字段
SELECT id, name, english + 10 FROM exam_result;
-- 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam_result;
别名
为查询结果中的列指定别名,表示返回的结果集中,以别名作为该列的名称,语法:
SELECT 列名 [AS] 别名 FROM 表名;
AS可以省略,但可读性变差了很多,所以不推荐
去重:DISTINCT
针对查询结果进行去重,如果存在重复数据,就会把重复的行合并成一行(如果查询包含多列,那么那几列都要相同才算重复)
使用DISTINCT关键字对某列数据进行去重:
select distinct 列名 from 表名;
排序:ORDER BY
- 没有 ORDER BY 子句的查询,返回的顺序是未定义的
- NULL 视为比任何值都小,升序出现在最上面,降序出现在最下面.如果存在多个NULL,多个NULL之间的顺序是不确定的
- ORDER BY默认是按照升序排序(ASC),如果要降序排序,需要加上DESC关键字
- 排序是以 行 为单位进行排序的
不同desc
desc 表名 是describe的缩写
order by 的 desc 是 descend的缩写
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM 表名 [WHERE ...] ORDER BY 列名/表达式 [ASC|DESC];
order by 后面写的列名/表达式不一定要在select后面的列名/表达式里出现
使用表达式及别名排序
-- 查询同学及总分,由高到低
SELECT name, chinese + english + math FROM exam_result ORDER BY chinese + english + math DESC;
SELECT name, chinese + english + math as total FROM exam_result ORDER BY total DESC;
- 可以对多个字段进行排序,排序优先级随书写顺序
SELECT ... FROM 表名 [WHERE ...] ORDER BY 列名/表达式 [ASC|DESC], 列名/表达式 [ASC|DESC]...;
先按照order by后面的第一列排序,再是第二列,第三列…
-- 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
SELECT name, math, english, chinese FROM exam_result ORDER BY math DESC, english, chinese;
条件查询:WHERE
NULL和其他值进行关系运算的结果也是NULL,NULL在SQL中可以隐式转成FALSE
SELECT ... FROM 表名 [WHERE ...]
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 比较相等,NULL 不安全,例如 NULL = NULL 的结果是 FALSE |
| <=> | 比较相等,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,如果 a0 <= value <= a1,返回 TRUE(1),注意是闭区间 |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)字符; _ 表示任意一个字符 |
- BETWEEN a0 AND a1描述的是"连续的区间"
- IN (option, …)描述的是"离散的集合"
- = 是精确查询,要求查询出的结果和条件中指定的内容完全一致
- like是模糊查询,只要有一部分一致即可, 比如
'孙%'匹配孙开头的内容。 这样的操作开销很大,性能很低,慎用
-- % 匹配任意多个(包括 0 个)字符
SELECT name FROM exam_result WHERE name LIKE '孙%';-- 匹配到孙悟空、孙权
-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到孙权
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0);条件为FALSE(0),结果为 TRUE(1) |
注:
- WHERE条件可以使用表达式,但不能使用别名。
查询的执行顺序:
1.遍历表
2.代入条件
3.计算列名中的表达式(定义别名)
4.排序/聚合等操作
所以执行where在定义别名前面
- AND的优先级高于OR,在同时使用时,需要使用()包裹优先执行的部分
分页查询:LIMIT
- limit关键字用来描述本次查询最多返回多少条记录
- 搭配offset关键字,offset称为偏移量(相当于下标), 不写offset就相当于offset 0.
假定一页显示 10条记录
第一页: limit 10 offset 0
第二页: limit 10 offset 10
…
如果结果不足10个不影响
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM 表名 [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM 表名 [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM 表名 [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
聚合查询(行与行之间的运算)
聚合函数
- 遇到NULL就会跳过
- 聚合函数的函数名和括号之间,不能有空格
常见的统计总数、计算平均值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
- COUNT
只有count的参数能是 * ,count(*) 相当于 先执行 select * from 表名 再对结果进行 count 聚合
*也可以换成具体的列名/表达式,如果写成具体的列名/表达式,就是针对这一列/表达式查询,再进行聚合
-- 统计班级共有多少同学
SELECT COUNT(*) FROM student;
SELECT COUNT(0) FROM student;
-- 统计班级收集的 qq_mail 有多少个,qq_mail 为 NULL 的数据不会计入结果
SELECT COUNT(qq_mail) FROM student;
1)可以帮我们获取到非空记录的数量
2)可以搭配 group by 进行分组
- SUM
-- 统计数学成绩总和
SELECT SUM(math) FROM exam_result;
-- 统计数学成绩 < 60 的总和,如果没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math < 60;
- AVG
-- 统计平均分数
SELECT AVG(chinese + math + english) as 平均总分 FROM exam_result;
- MAX
-- 返回英语最高分
SELECT MAX(english) FROM exam_result;
- MIN
-- 返回 > 70 分以上的数学最低分
SELECT MIN(math) FROM exam_result WHERE math > 70;
分组查询: GROUP BY子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 后必须包含在聚合函数中,不然没有意义。
select column1, sum(column2), .. from 表名 group by column1,column3;
案例

1.先执行 select role, id from emp
2.再根据group by role,按照 role 这一列的值针对上述查询结果进行分组
3.针对上述的每个组,分别执行 count 聚合操作,结果整理成临时表(这几个分组的顺序谁先谁后是不确定的),返回给客户端
还可以进行排序:

是可以针对聚合后的结果进行排序,而不是干预每个分组中数据的先后顺序
反例:

每个显示的结果都是每个分组中的其中一条记录,但是分组之后顺序都是不确定的,上述结果存在一定的"随机性",因此没有意义.
非 group by 的列,不应该直接写到 select 查询的列中(得搭配聚合函数)
给聚合查询指定条件
聚合之前的条件(WHERE 在 group by 之前)
举例:
查询每个岗位的平均工资,但是刨除"张三"

聚合之后的条件(HAVING 在 group by 之后)
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
举例:
查询每个岗位的平均工资,但是刨除平均工资超过1万的岗位(计算出每个岗位的平均工资之后才能进行上述条件筛选)

联合查询(多表查询)
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积(多表查询的基础):

列数就是原来的两个表的列数之和
行数就是原来两个表的行数之积
注意:联合查询可以对关联表使用别名。
多表联合查询的一般步骤
- 确定要查的信息来自哪几个表
- 把这些表进行笛卡尔积
- 指定连接条件
- 指定其他补充条件/聚合操作
- 针对列进行精简
内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
在SQL中, 可以很方便地通过 select 完成笛卡尔积

上述笛卡尔积中存在一部分无效/无意义的数据,如果数据不能反映客观的真实情况,这个数据就是无效的

在写条件的时候,给列名前面显式加上表名即可

如果class 的classId 改名为 class_id,这个时候前面不加表名.也行,但还是建议加上,有助于提高可读性
还有join on的写法

指定连接条件

外连接
外连接和内连接一样也是基于笛卡尔积的方式来计算,但对于空值/不存在的值,处理方式存在区别。
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
在两张表的数据"一 一对应"的情况下,内连接和外连接的结果是一样的
如果不能"一 一对应",内连接和外连接的结果就有所不同了

- 孙七的classId在 class 表中不存在
- class 表中 java104 在 student表中也不存在
对上述数据进行内连接,得到的结果就是只包含两个表都存在的数据

inner可以省略
外连接语法:
-- 左外连接,表1完全显示
select 列名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 列名 from 表名1 right join 表名2 on 连接条件;
左外连接会保证左侧表的每个数据都会存在,左侧表数据在右侧表不存在的部分会使用NULL表示

右外连接和左外连接类似,以右表为基准,使右表中的每个数据都存在,对应左表不存在的部分用NULL填充
自连接
自连接是指在同一张表连接自身进行查询。(自己和自己进行笛卡尔积)
案例:
显示所有“数据库”成绩比“数据结构”成绩高的成绩信息

直接进行自连接发现不行

要给表起别名

自连接能把行之间的关系转换成列之间的关系
子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
- 单行子查询:返回一行记录的子查询
select ... from 表1 where 字段1 = (select ... from ...);

查询’张三’的同班同学:

- 多行子查询:返回多行记录的子查询
案例:查询“数据结构”或“Java”课程的成绩信息

1. [NOT] IN关键字:
语法:
select ... from 表1 where 字段1 in (select ... from ...);
in

not in

2. [NOT] EXISTS关键字 (比 IN 效率低,但节省内存):
语法:
select ... from 表1 where exists (select ... from ... where 条件);
使用 EXISTS

使用 NOT EXISTS

- 在from子句中使用子查询:子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
select ... from 表1, (select ... from ...) as 临时表名 where 条件
查询所有比“数据库”平均分高的成绩信息:
第一步: 获取“数据库”的平均分,将其看作临时表

第二步:查询成绩表中,比以上临时表平均分高的成绩:

合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,列的类型/个数/顺序需要一致, 列名无所谓。
- union(去除重复数据)
select ... from ... where 条件
union
select ... from ... where 条件
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。

案例:查询3班或者1班的人:

相比于 or , union 可以从多个表分别查询
- union all (不去重)
select ... from ... where 条件
union all
select ... from ... where 条件
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
修改(Update)
会修改服务器硬盘上存储的数据
语法:
UPDATE 表名 SET 列名 = 值 [WHERE ...] [ORDER BY ...] [LIMIT ...]

也可以一次修改多个列,set后面写多组列,分别进行赋值即可
UPDATE 表名 SET 列名 = 值, 列名 = 值... [WHERE ...] [ORDER BY ...] [LIMIT ...]
修改也可以用表达式

此处不能写作 id += 10
删除(Delete)
删除是以 行 为维度进行删除的,删除的就是条件满足的数据.如果不指定条件,就是删除表中所有数据,不过删完全部数据之后表还是存在的,只不过是空的
语法:
DELETE FROM 表名 [WHERE ...] [ORDER BY ...] [LIMIT ...]
PS
SQL查询中各个关键字的执行先后顺序: from > on> join > where > group by > with > having >
select > distinct > order by > limit